Contexte
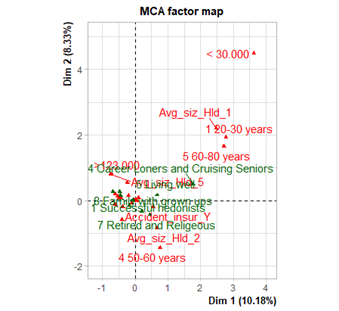
Ce projet avait pour but d’analyser deux jeux de données un sur le marché de l’automobile l’autre sur des données d’assurance afin de réaliser des méthodes de datamining. Dans une première partie dans notre projet, nous avons réalisé une analyse de segmentation du marché des assurance en utilisant plusieurs techniques d’analyse de données. Tout d’abord, nous avons chargé et préparé les données en les recodant pour avoir des libellés plus clairs sur les graphiques. Ensuite, nous avons effectué une Analyse en Composantes Multiples (ACM) pour explorer les variables qualitatives et extraire les dimensions principales permettant de mieux comprendre la structure. Cette étape nous a permis de visualiser les relations entre les différentes variables qualitatives, telles que l’âge moyen des clients, le type de contrat d’assurance et d’autres informations importantes.
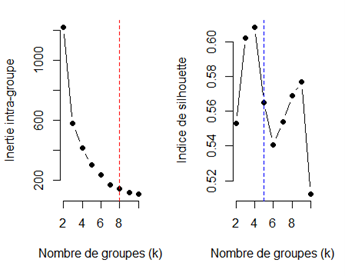
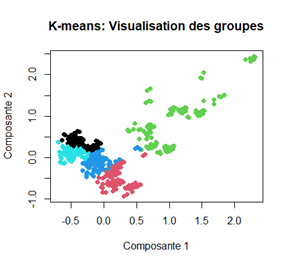
Après avoir effectué l’ACM, nous avons appliqué l’algorithme de K-means pour segmenter les données en groupes. Pour déterminer le nombre optimal de groupes, nous avons utilisé la méthode du coude ainsi que l’indice de silhouette. Cela nous a permis de choisir un nombre optimal de clusters, que nous avons ensuite utilisé pour effectuer le K-means sur les coordonnées issues de l’ACM. Nous avons visualisé les résultats en graphique, ce qui nous a permis de mieux comprendre la distribution des individus selon leurs caractéristiques.
Nous avons ensuite procédé à une analyse hiérarchique pour comparer les résultats obtenus avec le K-means et pour explorer si un autre découpage en groupes pouvait mieux refléter la structure des données. Nous avons découpé les individus en 5 groupes, puis visualisé les groupes résultants à l’aide d’un dendrogramme. En parallèle, nous avons visualisé la répartition des individus dans l’ACM selon les groupes définis par la CAH.
Dans un objectif d’interprétation plus précise, nous avons aussi étudié la variable Car_policie_REC (assurance automobile), en la mettant en avant dans nos visualisations. En analysant le nombre d’individus ayant une assurance automobile (Car_policie_Y) par groupe, nous avons pu mieux comprendre l’impact de cette variable sur la segmentation.
Enfin, nous avons conclu notre analyse en affichant les résultats de la segmentation, en mettant en évidence les groupes, et nous avons observé les caractéristiques des individus dans chaque groupe. Cette approche nous a permis de définir des marchés à potentiel et des groupes de clients.
Ce que j’ai appris
À travers ce projet, j’ai appris à appliquer des méthodes statistiques comme l’ACM, le K-means et la CAH pour segmenter un marché et comprendre les comportements des consommateurs. J’ai également découvert l’importance des variables qualitatives et comment les transformer pour les intégrer dans des analyses.
Compétences Mobilisés
Méthodes statistiques & exploration
- Réalisation d’une Analyse en Composantes Multiples (ACM) pour explorer les variables qualitatives
- Utilisation de l’algorithme K-means pour segmenter les données
- Réalisation d’une Classification Ascendante Hiérarchique pour comparer les segmentations
Segmentation & Analyse
- Analyse détaillée des variables
- Interprétation des groupes obtenus
- Mise en évidence des caractéristiques spécifiques à chaque segment
Analyse des données
- Application de méthodes de segmentation de marché sur des jeux de données
- Nettoyage, recodage et préparation des données
- Visualisation et interprétation des relations entre variables